Abstract
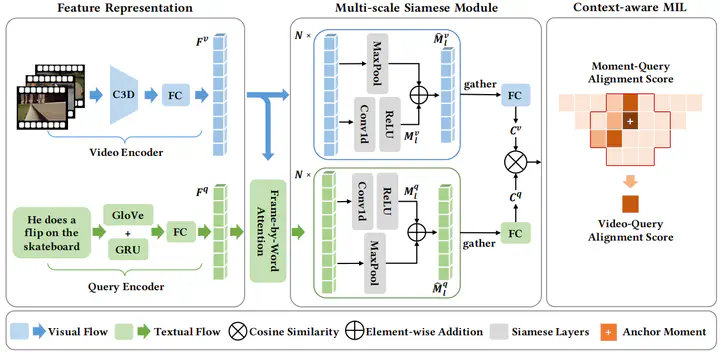
Video moment retrieval, i.e., localizing the specific video moments within a video given a description query, has attracted substantial attention over the past several years. Although great progress has been achieved thus far, most of existing methods are supervised, which require moment-level temporal annotation information. In contrast, weakly-supervised methods which only need video-level annotations remain largely unexplored. In this paper, we propose a novel end-to-end Siamese alignment network for weakly-supervised video moment retrieval. To be specific, we design a multi-scale Siamese module, which could progressively reduce the semantic gap between the visual and textual modality with the Siamese structure. In addition, we present a context-aware multiple instance learning module by considering the influence of adjacent contexts, enhancing the moment-query and video-query alignment simultaneously. By promoting the matching of both moment-level and video-level, our model can effectively improve the retrieval performance, even if only having weak video level annotations. Extensive experiments on two benchmark datasets, i.e., ActivityNet-Captions and Charades-STA, verify the superiority of our model compared with several state-of-the-art baselines.
Yunxiao Wang
Ph.D. Candidate of Artificial Intelligence
My research interests include multimedia computing, affective computing and information retrieval.